Hinweis: Dieser Artikel ist ein Beitrag zum ScienceBlogs Blog-Schreibwettbewerb 2016. Hinweise zum Ablauf des Bewerbs und wie ihr dabei Abstimmen könnt findet ihr hier.

Das sagt der Autor des Artikels, kein Name über sich:
Ich habe Physik studiert, arbeite aber inzwischen in der Industrie. Meine Freude an der Wissenschaft habe ich aber nicht verloren und so gehe ich gerne in Vorträge oder lese in aktuellen Veröffentlichungen. Mein besonderes Interesse ist zur Zeit das menschliche Gehirn und warum wir ihm nicht immer trauen dürfen.
——————————————
Das Lesen von wissenschaftlichen Studien oder wie signifikant ist „Statistische Signifikanz“?
Ich finde, es lohnt sich, bei Artikeln zu wissenschaftlichen Erkenntnissen auch die Originalstudie zu lesen, besonders bei Klassikern oder bei Durchbrüchen in der Wissenschaft.
Für mich war dieses Jahr das bisherige Highlight dabei der direkte Nachweis von Gravitationswellen (und nicht nur, weil es beinahe an meinem Geburtstag veröffentlicht wurde):
Observation of Gravitational Waves from a Binary Black Hole Merger [1]
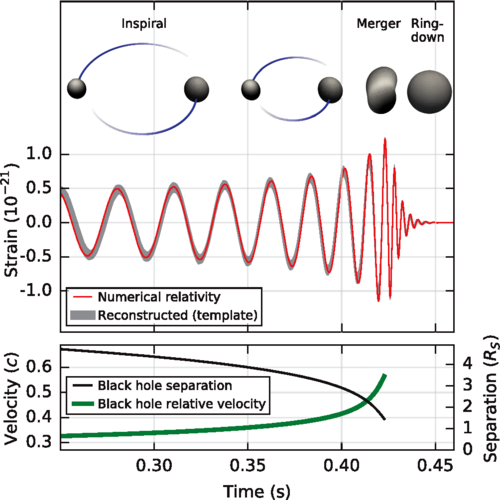
Abbildung 1: Verlauf der Verschmelzung zweier Schwarzer Löcher
Dabei gibt es ein paar Aspekte, die mir bei diesem Paper besonders gefallen. Das Paper
– ist für ein Thema an der Speerspitze der Forschung eigentlich sehr verständlich,
– zeigt kurz den Weg von der theoretischen Vorhersage über die
– ersten indirekten Nachweise im Doppelpulsar zum
– aktuellen Experiment,
– beschreibt das zugrunde liegende physikalische Phänomen und
– den verwendeten Versuchsaufbau.
Im Abstract, also in der Zusammenfassung des Papers, findet man an zahlenmäßigen Angaben zusätzlich zu den physikalischen Daten wie den Massen der Schwarzen Löcher, deren Abstand von der Erde und der abgestrahlten Energie noch eine weitere Angabe nämlich
to a significance greater than 5.1σ

Abbildung 2: Teils des Abstracts zum Paper
Weil ich dieses Konzept der Statistischen Signifikanz einerseits interessant und andererseits auch grundlegend für das Verständnis eines jeden Papers finde, will ich es hier in diesem Beitrag vorstellen. Dabei ist die Anwendung nicht nur auf die Physik beschränkt; die statistische Signifikanz kann man in allen Wissenschaftsfeldern antreffen, von der Physik über Chemie, Biologie bis hin zu Medizin und Psychologie.
Was außerdem noch dazukommt, ist, dass der Begriff nicht selbsterklärend ist und damit leicht zu Missverständnissen einlädt. Das hat gerade in letzter Zeit in der Fachwelt für Diskussionen gesorgt – so weit, dass dieses Jahr die American Statistical Association (ASA) zu diesem Thema ein Positionspapier [2] herausgegeben hat.
Das Wichtigste in Kürze
Von Statistischer Signifikanz wird in wissenschaftlichen Publikationen von Studienergebnissen gesprochen, wenn die Wahrscheinlichkeit, dass ein Testergebnis durch Zufall zustande gekommen ist, nicht über einer durch das Signifikanzniveau vorgegebenen Wahrscheinlichkeit liegt. Entgegen einer häufigen Vorstellung beschreibt das Signifikanzniveau damit nicht die Wahrscheinlichkeit, dass das Studienergebnis korrekt ist. Unkritisches und übertriebenes Vertrauen in die Statistische Signifikanz kann zu möglichen Fehlerquellen wie Publication Bias (Verzerrung aufgrund selektiver Veröffentlichung) und p-Hacking (nachträgliche Veränderung von Studien, um ein vorgegebenes Signifikanzniveau zu erreichen) führen, so dass inzwischen andere Ansätze zur Beurteilung der Qualität von Studien (Analyse mittels Bayes-Formel) an Bedeutung gewinnen.
So kurz so gut. Wenn wir uns näher mit dem Thema beschäftigen wollen, dann helfen die folgenden
Wichtigen Definitionen
p-value
Für ein beobachtetes, statistisches Messergebnis gibt der p-value die Wahrscheinlichkeit an, dass ein solches oder ein noch extremeres Ergebnis durch Zufall auftritt. Dazu wird das Gegenteil der Hypothese – eine Nullhypothese angenommen. Häufig ist das die Hypothese, dass gar kein Effekt vorhanden ist. Der p-value beschreibt dann, wie hoch die Wahrscheinlichkeit ist, dass trotz Vorliegen der Null-Hypothese das beobachtete Ergebnis durch Zufall auftritt.
Signifikanzniveau
Das Signifikanzniveau bezeichnet eine vorgewählte Wahrscheinlichkeit, ab der akzeptiert wird, dass ein Ergebnis wahrscheinlich nicht durch Zufall zustande gekommen ist. Das Signifikanzniveau ist im Prinzip frei wählbar. Häufig wird eine 95-prozentige Sicherheit gefordert, d.h. wenn kein Effekt vorliegt, dann soll nur in 5 % der Fälle ein Test fälschlicherweise ein positives Ergebnis liefern.
Statistische Signifikanz
Ein Ergebnis wird dann als statistisch signifikant bezeichnet, wenn sein p-value unter dem Signifikanzniveau liegt.
Sigma (σ)
In diesem Zusammenhang bezieht sich der griechische Buchstabe Sigma auf die Standardabweichung einer Normalverteilung. Diese ist so definiert, dass sich 68% der Werte einer zufälligen Verteilung in einem Bereich plus/minus einer Standardabweichung vom Mittelwert befinden und 32% außerhalb. Erweitert man den Bereich auf plus/minus 2 Sigma, dann liegen nur noch 5% der Ergebnisse außerhalb. Im zitierten Paper wird eine Signifikanz von 5,1 Sigma angegeben. Das bedeutet, dass die Wahrscheinlichkeit für einen Falschalarm (nämlich, dass das Ergebnis eine zufällige Schwankung des Hintergrundrauschens ist) kleiner als 2 × 10E-7 ist.
Und weil ich ja oben schon gesagt habe, dass ich gerne die Originalarbeiten zu einem Thema lese, habe ich natürlich auch zur Statistischen Signifikanz die erste Arbeit gesucht:
Geschichte
Der p-value wurde von Ronald Fisher [3] 1925 entwickelt, um einfach entscheiden zu können, ob ein Messergebnis ernst zu nehmen ist oder möglicherweise nur einen statistischen Ausreißer darstellt. Aufgrund der einfachen Verwendbarkeit durch Reduktion auf eine einzige Zahl hat der p-value große Verbreitung gefunden. Zunehmende Kritik an der unkritischen Verwendung des Konzepts der Statistischen Signifikanz (siehe z. B. Regina Nuzzo [4]) hat die American Statistical Association (ASA) dazu bewogen, 2016 ein Positionspapier [2] zu veröffentlichen, dass ausdrücklich vor einer missbräuchlichen Verwendung des p-values warnt.
Nachdem wir die trockenen Definitionen und die Geschichte hinter uns haben – ich tue mir immer leichter die abstrakten Erklärungen zu verstehen, wenn ich an einem konkreten Beispiel selber rechnen kann. Also kommen wir zur
Anwendung
Typischer Anwendungsbereich sind Studien z. B. in der Medizin, in denen zwei oder mehr Gruppen (Patienten oder Versuchstiere) sich in einer oder mehreren Variablen z. B. unterschiedliche Behandlung, aber auch Differenzen der Gruppen (Ernährung, Lebensweise, BMI, Raucher/Nichtraucher, …) voneinander unterscheiden. Da Krankheitsverläufe für verschiedene Personen und selbst für Versuchstiere einer Zucht/genetischen Linie unterschiedlich verlaufen, ist normalerweise das Ergebnis im Einzelfall nicht vorhersagbar. Um Aussagen machen zu können, werden die Ergebnisse der einzelnen Gruppen zusammengefasst – man kommt also um etwas Statistik nicht herum.
Anwendungsbeispiel
Es soll eine neue Behandlungsmethode für eine Erkrankung getestet werden, bei der sich ohne Behandlung 50% der Patienten von alleine erholen. Die neue Behandlungsmethode wird an 100 Personen getestet.
Aufgabenstellung
Ab wie vielen geheilten Patienten im Test kann davon ausgegangen werden, dass ein positives Behandlungsergebnis mit einer Sicherheit von mindestens 95% nicht durch Zufall entstanden ist, also signifikant ist?
Lösung
Nullhypothese ist hier also, dass die Behandlung keinen Effekt hat – dennoch kann ein Forscher auf den Fall stoßen, dass zufälligerweise mehr als die Hälfte der Patienten in der Studie geheilt werden. Jetzt müssen wir herausbekommen, wie wahrscheinlich das ist.
Für die genaue Lösung muss man auf die Formeln für die Binomial- bzw. näherungsweise auf die Gaußverteilung zurückgreifen. Zur Anschauung wird hier die Lösung aber graphisch hergeleitet.
Im folgenden Diagramm wird gezeigt, mit welcher Wahrscheinlichkeit jedes Ergebnis, also eine bestimmte Zahl von geheilten Patienten, vorkommt, wenn man für jeden einzelnen der 100 Patienten jeweils unabhängig eine Heilungswahrscheinlichkeit von 50% ansetzt. (Man kann sich vorstellen, dass man für jeden Patient eine Münze – Heilung oder nicht – wirft. Das Problem ist mathematisch äquivalent.)
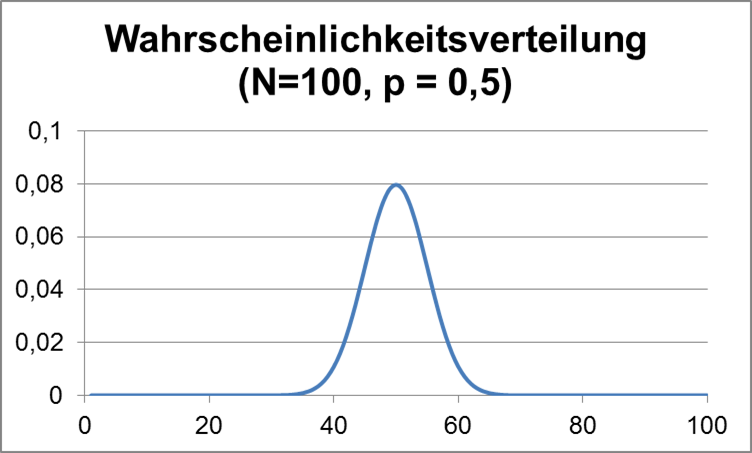
Abbildung 3: Wahrscheinlichkeitsverteilung für 100 Münzwürfe
Wie man sieht, ist z. B. die Wahrscheinlichkeit in einem Versuch genau 50 geheilte Patienten zu finden 0,08 = 8%. Die Wahrscheinlichkeiten nehmen links und rechts dazu schnell ab, d. h. größere Abweichungen vom mittleren Wert sind selten.
Für die Aufgabe ist nun zu bestimmen, wo man eine Linie in dem obigen Diagramm setzen müsste, dass 95% der Ergebnisse sich links davon befinden, so dass die Wahrscheinlichkeit für ein Ergebnis rechts der Linie nur noch 5% beträgt.
Die Summe aller Wahrscheinlichkeiten für ein Ergebnis kleiner einer Zahl ist in der folgenden Graphik gezeigt:
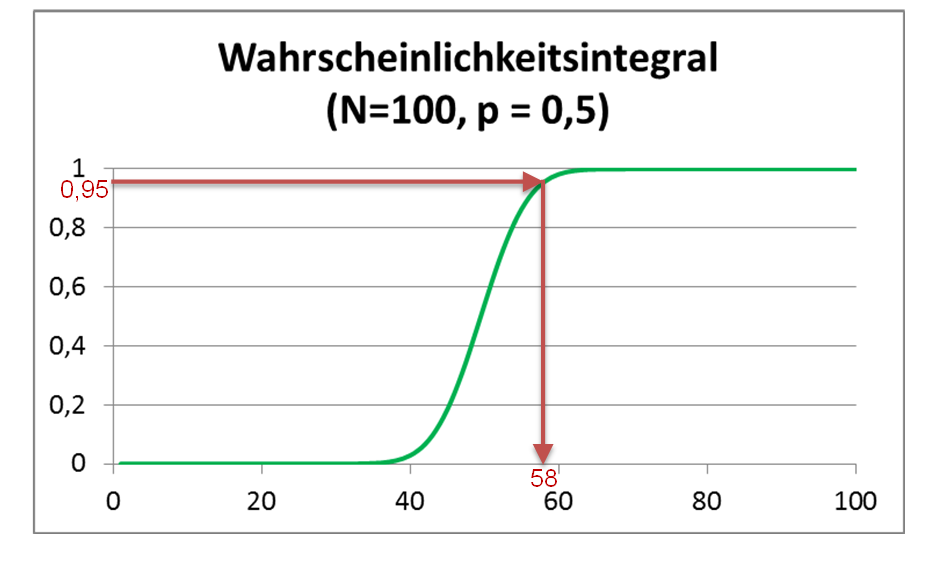
Abbildung 4: Wahrscheinlichkeitsintegral für 100 Münzwürfe
Durch die roten Linien im Diagramm ist gezeigt, wie man die zu einer integrierten Wahrscheinlichkeit von 95% gehörige Anzahl von geheilten Personen ablesen kann. In unserem Beispiel ergibt sich, dass erst wenn mindestens 58 Personen im Test geheilt wurden, man sich zu 95% sicher sein kann, dass nicht nur durch einen glücklichen Zufall überdurchschnittlich viele Testpersonen geheilt wurden.
Trotz allem – auch die Statistische Signifikanz ist nur ein Werkzeug und wie jedes andere Werkzeug kann auch dieses falsch eingesetzt werden. Daher ist es also gut, die diversen Fallstricke zu kennen, um nicht selber darauf hereinzufallen (gerade bei der eigenen Lieblingstheorie muss man besonders vorsichtig sein – unser Hirn macht uns da gerne etwas vor) oder sich etwas unterschieben zu lassen (Marketing, sensationshungrige Presse, politische Interessen, Profitgier, skrupellose Kollegen – hier können Sie Ihr eigenes Feindbild einsetzen – könnten versucht haben, dass Ergebnis in deren Richtung zu verschieben).
Diskussion
Es muss darauf hingewiesen werden, dass es für die Interpretation der Signifikanz in obigem Beispiel wesentlich ist, dass die Fragestellung im Voraus und eindeutig formuliert wurde und keine weiteren Fragestellungen in Betracht gezogen wurden. Mögliche Fehlerquellen könnten sein: Der Forscher erhebt verschiedene Datensätze (z. B. könnte der Heilerfolg an verschiedenen Tagen und an Hand verschiedener Parameter (Patientenbefragung, Laborwerten, Verbrauch an Schmerzmitteln) erfasst werden). Damit erhöht sich die Chance, bei einem der Parameter einen signifikanten Effekt zu sehen.

Abbildung 5: xkcd-Comic significance
Was auch geht, der Forscher ändert die Fragestellung (z. B. könnte der Forscher beschließen, auch eine deutlich geringere Zahl von geheilten Patienten wäre ein Nachweis, dass eine Behandlung anschlägt (Erstverschlimmerung) und somit würde er nachträglich auch Ergebnisse z. B. unter 42 geheilten Patienten als signifikant berichten.
Des Weiteren sagt das Signifikanzniveau nicht direkt etwas über die Wahrscheinlichkeit aus, dass bei einem positiven Testergebnis die Hypothese richtig ist. Gerade beim Test von a priori unwahrscheinlichen Hypothesen ergibt sich zwingend, dass die meisten positiven Testergebnisse falsch sind und zufällig entstanden sind [5] (für ein Rechenbeispiel hierzu siehe Kann ich meinem Hirn trauen? (3. Teil)).
Kritik
Fehlerhafte Interpretationen von Statistischer Signifikanz
Statistische Signifikanz macht keine Aussage darüber, ob die Hypothese richtig ist. Es wird nur angegeben, wie wahrscheinlich bei zutreffender Null-Hypothese das vorliegende Ergebnis ist. Alternative Hypothesen, die das vorliegende Ergebnis ebenso gut oder besser erklären können, werden nicht berücksichtigt. Statistische Signifikanz macht keine Aussage über die Größe oder Relevanz eines Effekts. Mit entsprechend aufwändigen Tests (z. B. mehr Versuchspersonen) können auch kleine Effekte signifikant nachgewiesen werden, auch wenn diese Effekte in der Praxis vernachlässigt werden können.
Willkürliche Definition der Schwelle für statistische Signifikanz
Der häufig verwendete Wert für das Signifikanzniveau von 0,05 ist willkürlich gewählt und gerade bei Tests von grundlegender Bedeutung zu niedrig angesetzt. In der Physik wird deshalb als Schwelle für den Nachweis von bisher nicht bestätigten Phänomenen ein Signifikanzniveau von p < 3 × 10E-7 (entsprechend 5σ) verwendet (wie oben im Paper zum Nachweis der Gravitationswellen, aber auch beim Nachweis des Higgs-Bosons [6]), obwohl es sich dabei um theoretisch erwartete Phänomene mit vorhandenen indirekten Hinweisen ihrer Existenz handelte. Für gänzlich unerwartete Effekte müsste die Schwelle daher sogar noch höher angesetzt werden. Hier muss ich noch einen Seitenhieb auf diverse Pseudowissenschaftler loswerden – wenn man schon versucht, neue Physik wie ein Gedächtnis des Wassers etc. zu etablieren, dann ist schon mehr als Nachweis nötig als eine „signifikante“ Studie mit Signifikanzniveau 5%).
Bayes-Analyse als Alternative zum p-value
Als Alternative zum p-value schlagen Goodman [7] und Steven Novella [8] vor, bei der Analyse von Studienergebnissen den Satz von Bayes zu verwenden. Im Gegensatz zum p-value kann durch den Satz von Bayes vorhergehendes Wissen zur Wahrscheinlichkeit einer Hypothese mit herangezogen werden. Die bayessche Statistik kann dann angeben, wie sich eine a priori vorhandene Wahrscheinlichkeit durch neue Studienergebnisse verändert. Ein Punkt der hingegen an der Bayes-Analyse kritisiert wird, ist, dass ohne vorheriges Wissen die Festlegung der a priori Wahrscheinlichkeit ebenfalls willkürlich ist. Z. B. können verschiedene Personen ganz unterschiedlicher Meinung sein, wie wahrscheinlich vor einer Studie die Wahrscheinlichkeit ist, dass etwa Homöopathika irgendeine Wirkung haben. Allerdings zwingt die Bayes-Analyse einen dazu, sich dazu Gedanken zu machen, diese zu quantifizieren und die eigene Wahl zu begründen.
Statistische Signifikanz als Schranke für die Veröffentlichung
Häufig wird ein Erreichen eines Signifikanzniveaus von p < 0,05 als Voraussetzung für eine Veröffentlichung in einer Fachzeitschrift gefordert. Dies führt zu einer Verzerrung (publication bias) der Ergebnisse, so dass statistische Ausreiser übermäßige Bedeutung bekommen, während Ergebnisse, die keinen Effekt zeigen, verloren gehen. Durch das Fehlen der erfolglosen Studien wird eine Wirksamkeit vorgetäuscht, die in Wirklichkeit nicht vorhanden ist. Daher ist zum Beispiel die Fachzeitschrift Basic and Applied Social Psychology dazu übergegangen, in ihren Veröffentlichungen den p-value nicht mehr zu verwenden [9].
Veränderung von Studien um Signifikanz zu erreichen („p-hacking“ or „researcher degrees of freedom“)
Simonsohn, Nelson und Simmons konnten nachweisen [10], dass sich die p-values in Veröffentlichungen auffällig häufig knapp unter 0,05 häufen. Als möglichen Grund führen sie an, dass Freiheiten des Forschers bei der Datensammlung, Analyse und Darstellung es erlauben, die vorliegenden Daten auch bei feststehender Fragestellung auf vielerlei Weise auszuwerten [11]. Ein Forscher könnte z. B. eine Befragung dann verlängern, wenn sich noch kein signifikanter Effekt zeigt und dann beenden, wenn die Signifikanz erreicht wurde. In [12] zeigen Andrew Gelmany und Eric Lokenz beispielhaft an realen Papern wie so etwas vor sich gehen kann.
Dass in der akademischen Welt ein gewisser Druck herrscht, zu veröffentlichen und dafür signifikante Ergebnisse produziert werden müssen, verschärft das Problem noch.
Ein Ansatz, den Einfluss sowohl von nicht veröffentlichten als auch von im Verlauf abgeänderten Studien zu begrenzen, ist die Initiative AllTrials[12], die u. a. fordert, Studien noch vor ihrem Beginn und einschließlich einer Beschreibung des geplanten Vorgehens zu registrieren.
Und weil es dort schon so schön zusammengefasst wurde, will ich aus dem oben erwähnten Positionspapier der American Statistical Association zitieren für das
Schlusswort
„Gutes statistisches Vorgehen, als ein wesentlicher Bestandteil guten wissenschaftlichen Vorgehens, betont die Prinzipien guten Studiendesigns und guter Durchführung einer Studie, eine Vielfalt von zahlenmäßigen und graphischen Zusammenstellungen der Daten, ein Verständnis des untersuchten Phänomens, die Interpretation der Ergebnisse im Kontext, das vollständige Offenlegen und geeignetes logisches und quantitatives Verständnis davon, was die Datenzusammenstellungen bedeuten.
Kein einzelner Zahlenwert sollte das wissenschaftliche Denken ersetzen.“
Quellen- und Literaturangaben
[1] B.P. Abbott et al. (LIGO Scientific Collaboration and Virgo Collaboration) Phys. Rev. Lett. 116, 061102 – Published 11 February 2016 https://journals.aps.org/prl/abstract/10.1103/PhysRevLett.116.061102
[2] Ronald L. Wasserstein & Nicole A. Lazar 2016): The ASA’s statement on p-values: context, process, and purpose, The American Statistician, https://dx.doi.org/10.1080/00031305.2016.1154108
[3] Fisher, Ronald A. (1925). Statistical Methods for Research Workers. Edinburgh, UK: Oliver and Boyd. p. 43. ISBN 0-050-02170-2
[4] Spektrum der Wissenschaft, 2014, Regina Nuzzo:„Wenn Forscher durch den Signifikanztest fallen“ https://www.spektrum.de/news/statistik-wenn-forscher-durch-den-signifikanztest-fallen/1224727 (aufgerufen am 27.März 2016), Original: „Statistical errors“, Nature 506, S. 150-152, 2014 https://www.nature.com/news/scientific-method-statistical-errors-1.14700 (aufgerufen am 30.März 2016)
[5] Why Most Published Research Findings Are False; John P. A. Ioannidis; PLOS; Published: August 30, 2005; https://dx.doi.org/10.1371/journal.pmed.0020124
[6] CERN experiments observe particle consistent with long-sought Higgs boson. Pressemitteilung von CERN. 4.Juli 2012. https://press.cern/press-releases/2012/07/cern-experiments-observe-particle-consistent-long-sought-higgs-boson aufgerufen am 7.4.2016
[7] Toward Evidence-Based Medical Statistics. 2: The Bayes Factor; Steven N. Goodman, MD, PhD; Ann Intern Med. 1999 Jun 15;130(12):1005-13
[8] P Value Under Fire; Steven Novella; 9.3.2016 https://www.sciencebasedmedicine.org/p-value-under-fire/#more-41146 aufgerufen am 7.4.2016
[9] Psychology journal bans P values; Chris Woolston; 09 March 2015;
https://www.nature.com/news/psychology-journal-bans-p-values-1.17001 aufgerufen am 11.4.2016
[10] P-curve: A key to the file-drawer; Simonsohn, Uri; Nelson, Leif D.; Simmons, Joseph P.; Journal of Experimental Psychology: General, Vol 143(2), Apr 2014, 534-547. https://dx.doi.org/10.1037/a0033242
[11] False-Positive Psychology: Undisclosed Flexibility in Data Collection and Analysis Allows Presenting Anything as Significant; Joseph P. Simmons, Leif D. Nelson und Uri Simonsohn; https://www.ncbi.nlm.nih.gov/pubmed/22006061
[12] The garden of forking paths: Why multiple comparisons can be a problem, even when there is no \
shing expedition“ or \p-hacking“ and the research hypothesis was posited ahead of time;Andrew Gelmany and Eric Lokenz
https://www.stat.columbia.edu/~gelman/research/unpublished/p_hacking.pdf
[13] https://www.alltrials.net/find-out-more/all-trials
Originalzitate
„Good statistical practice, as an essential component of good scientific practice, emphasizes principles of good study design and conduct, a variety of numerical and graphical summaries of data, understanding of the phenomenon under study, interpretation of results in context, complete reporting and proper logical and quantitative understanding of what data summaries mean. No single index should substitute for scientific reasoning.“
aus Ronald L. Wasserstein & Nicole A. Lazar 2016): The ASA’s statement on p-values: context, process, and purpose, The American Statistician, https://dx.doi.org/10.1080/00031305.2016.1154108
Bildnachweis
Abbildung 1 und 2: aus B. P. Abbott et al. (LIGO Scientific Collaboration and Virgo Collaboration) Phys. Rev. Lett. 116, 061102 – Published 11 February 2016 Creative Commons Attribution 3.0 License
Abbildung 3 und 4: Autor
Abbildung 5: xkcd-Comics, Randall Munroe, https://xkcd.com/882/, Creative Commons Attribution-NonCommercial 2.5 License
Sehr informativer Artikel, vielen Dank an den Autor, das ganze mal so einfach zu formulieren (und die Wirren meines Mathematiklehrers zu dem Thema zu entschlüsseln. Der wusste zwar, wie das ganze funktioniert, hatte aber keine Ahnung, warum, oder wofür das gut sein soll, und hielt das auch nicht für besonders wichtig)
Eine Frage hab ich aber bzw. eine Sache hab ich nicht verstanden: wie komm ich denn von „5,1 Sigma“ auf „2 × 10E-7“?
(Oh, und die kleinen griechischen Sigma wurden scheinbar nicht richtig kodiert, bei mir steht stattdessen jeweils der html-Code selbst einsam in der Gegend rum.
@Florian: kanns sein, dass da Irgendwas dafür sorgt, das man wirklich nur den Text selbst sieht bzw. das verhindert, dass man Html hernehmen kann?)
Vielen Dank für diesen informativen und gut zu lesenden Artikel!
Es leuchtet intuitiv ein, dass das mit den Jelly Bean Farben und der Akne keinen Sinn ergibt. Kann mir jemand kurz erklären, warum das auch aus statistischer Sicht falsch ist? D.h. Wie erhöht sich bei der Betrachtung vieler Parameter die Wahrscheinlichkeit dass zufällig einer davon signifikant erscheint?
Ich weiss, dass ich in so einem Fall einen ANOVA test benutzen müsste, aber mir ist entfallen, warum.
@ Till: Signfikanzniveau von 5 heißt ja im Prinzip „Die Chance einer zufälligen positiven Korrelation beträgt 5%“. Wenn wir 20 Dinge untersuchen ist die Chance als hoch, dass 5% (=1) zufällig positiv ist.
Umgehen lässt sich das, in dem man die positiven Tests wiederholt oder das Signifikanzniveau senkt.
@Till: Naja, jede dieser kleinen Jelly-Bean-Studien ist mit einer Wahrscheinlichkeit von 5% falsch. Anders gesagt: (durchschnittlich) jede Zwanzigste ist das Ergebniss eines Zufalls. Jetzt zähl mal, wieviele Studien da insgesamt aufgelistet sind …
Wenn mans oft genug probiert, dann passiert halt auch das unwahrscheinliche irgendwann mal (deshalb ja die 2 × 10E-7. Dass da was Zufall ist, ist schon sehr unwahrscheinlich, wenn auch nicht auszuschließen. Aber das ist es ja eigentlich nie …)
Oh, da war wohl jemand schneller …
@Gazyrlezon
Auf den Wert 2e-7 kommt man, wenn man eine Normalverteilung annimmt (was in der Praxis oft gerechtfertigt ist, Grenzwertsatz) und das Wahrscheinlichkeitsintegral (s.o.) für eine Abweichung größer 5.1 Sigma berechnet. Google einfach mal Normalverteilung oder Gaußsche Glockenkurve.
Ich habe auch vergessen, ausdrücklich zu sagen, dass mein Name im Artikel stehen darf – aber ja, das ist mein Text.
@Gazyrlezon:
Hast recht – da ist was schief gelaufen, jedenfalls sollten die σ griechische Sigmas sein.
@Gazyrlezon, peer:
Ihr wart schneller, genau das war gemeint.
@Peter H.
Schöner Artikel, sehr klar und informativ! Das Thema wurde hier im Blog auch immer mal behandelt, aber dieser Artikel brachte mir nochmal einen (signifikanten?) Erkenntnisgewinn. (=> der Punkt, ab dem man sich das vielleicht endlich mal merken kann.)
@Till
Da kann ich noch diese Seite empfehlen:
https://www.explainxkcd.com/wiki/index.php/882
Oha! Ich sehe gerade, dass ich mich bei dem Artikel verplant habe. Der Stand eigentlich erst für 13. Oktober auf meiner Liste. Nun ja – gibt es heute halt 3 Beiträge und am 13.10 dann nur einen. Sorry…
@AlterPirat: Vielen Dank!
#Dampier: Stimmt, explainxkcd.com gibts ja auch noch. Ganz vergessen …
@peer, Gazyrlezon, Dampier
Danke für die schnellen und informativen Antworten! ich glaube ich habs jetzt. Wenn man mehrere Parameter einbezieht, dann verhält sich das gesamte Signifikanzlevel wie folgt: p(gesamt)=1-(Produkt(1-p(einzeln))). D.h. man berechnet die kombinierte Wahrscheinlichkeit, dass einer der parameter zufällig signifikant war. im Beispiel von xkcd mit 20 Parametern und jeweils p=0.05 ist der kombinierte p Wert also 1-(0.95^20)=0.64.
@Till: Bin zwar kein Experte mit Signifikanztests, aber das kling eigentlich ganz richtig.
Da sind wohl anderweitig einige „;“ benötigt worden, Peter, mit je einem hätten die σ funktioniert. Macht aber nix, ziemlich eindeutig, was gemeint war…
Gut geschriebene Übersicht, btw
Jaja, bei der Kommentareingabe kann es weggelassen werden, aber nur, weil es der Eingabefilter ergänzt.
Ich habe auch die Kommentarfunktion zum Testen des Layouts verwendet. Zum Glück habe ich keine Sonderzeichen verwendet. Mal sehen, ob der Rest o.k. ist.
btw. Alderamin hatte bei einem seiner ersten Gastartikel mal das gleiche Problem. Es passiert also auch den besten unter uns 😉
ErgänzungsFilter sind mir was ‚Filtern‘ angeht schon immer die liebsten gewesen, rolak^^
Schöner Artikel! Vielen Dank!
Was heißt hier ‚also‘, Till – gerade wer viel mit einem System arbeitet (und somit darin immer besser wird), tendiert dazu, die Faulheits-dankbar angenommenen Automatismen bei Systemwechseln zu vergessen. Zumindest aber intensiv zu vermissen.
..demnächst schlicht den bisherigen Text als .htm oder .html abspeichern und per Klick mit dem browser der Wahl inspizieren.
Bei der Bildgestaltung laufen solche zB als EffektFilter, LasurCyan.
Diese Eingabe-von-Unerwünschtem-befreien-Filter sind bzw waren in der Intention völlig filter-sprachnormal – doch dann evolvier(t)en sie unweigerlich durch user-Faulheit ;‑)
ein kompliziertes thema erhellend erleuchtet. danke dafür!
@rolak:
Ich habe meinen Textdatei mit html benannt und dann im IE angezeigt – da hatte es noch geklappt. Aber es ist auch so anscheinend noch verständlich geblieben.
***MIST***
Damusstedoch tatsächlich irgendsoeinen tiefverborgenen Umschalter suchen der bei ‚lazy html‘ das Licht ausmacht, Peter H, sorry.
Ausprobiert hatte ich speziell das selbstverständlich nicht, also mit unicode in html ohne beendendes Semikolon. Anderes schon. Häufig.
Doch da nutze ich typischerweise ein Tastaturmakro wie zB ⁶ aka <b>⁶</b> und klatsche die unicode#H rein, was a) recht bequem und b) offensichtlich recht stabil ist.
Mir nicht. Im Farbstoff könnte doch eine ungesunde Substanz enthalten sein.
der ist hübsch: da wurde schon wieder überinterpretiert, orijinool waren alle Sonderzeichen maskiert, doch offensichtlich teils nur so schwach verbergend wie bei den typischen Superhelden – gereicht hats bloß für die Vorschau… <b>& # 8310 ;</b>
Da hat doch uu das Bevölkerungsreduktionsprogramm vermittels grüner Geleebohnen offenbart… Er selber nimmt ja seit Jahren nur die in Magenta.
@rolak:
Ich weise jede Verbindung zur Telekom weit von mir. Oder verortest Du mich etwa in FDP-Nähe? Persönlich bevorzuge ich weiße Gummibärchen, bzw. die farblosen, aber nicht aus pharbfobie, sondern weil sie am besten schmecken. US-Jellybeans habe ich aber ncoh nicht probiert, da müsste mir jmd. ein Kilo für ausgiebige Tests erst zuschicken.
Ich hoffe Du hast erkannt, dass ich nur bestreite, dass eine Aussage als sinnlos einleuchtet und damit keineswegs behaupte, dass die Aussage als sinnvoll einleuchtet.
@user unknown
Das ist schon richtig. Mir ging es um die statistische Sichtweise: Intuitiv war mir klar, dass die Wahrscheinlichkeit ein falsch positives Ergebnis zu bekommen steigt, wenn man viele Parameter untersucht und jeden nur einzeln und unabhängig von den anderen auf Signifikanz überprüft. Ich wollte aber die Mathematik dahinter verstehen, deshalb die Nachfrage. Das hat dann ja auch mit Hilfe einiger freundlicher Hinweise geklappt (siehe meinen Post #11).
@rolak
Das funktioniert aber auch nicht zuverlässig, da die Blog software in den Texten nur einen Teil der HTML Befehle akzeptiert. Deshalb die Tests mit den Kommentaren, ob die html Tags die ich verwende auch unterstützt werden.
Für den nächsten Wettbewerb fände ich es schön, wenn Florian einen Beispieltext mit den möglichen Formatierungen zur Verfügung stellen könnte. Dann kann man sich daran orientieren (und ihm Formatierungsarbeit ersparen)
Quatsch, Till, das macht WordPress. Und kann/wird es ggfs ändern.
@rolak Danke für den Link. Ich war mir nicht sicher, dass der blog auf WordPress aufsetzt. Es gibt ja noch einige andere Blogsysteme. Habe eben aber den Link auf wordpress.org auf der Seite gefunden 😉
Ich denke trotzdem, dass ein Template helfen würde. Da vermutlich viele (oder sogar die meisten) Einsender nicht mit WordPress vertraut sind.
Du schreibst „dass ein positives Behandlungsergebnis mit einer Sicherheit von mindestens 95% nicht durch Zufall entstanden ist, also signifikant ist“, was denke ich nicht korrekt ist.
Ich zumindest interpretiere das folgendermaßen: „Die Wahrscheinlichkeit, dass die Nullhypothese nicht zutrifft, ist 95 %“.
Wie du allerdings selbst schreibst, bedeutet ein p-Wert von 5% nur, dass das Ergebniss (oder ein extremeres) unter Annahme der Nullhypothese mit 5% Wahrscheinlichkeit zustande käme. Der zulässige Umkehrschluss ist dann doch nur, dass ein weniger extremeres Ergebnis unter Annahme der Nullhypothese mit einer Wahrscheinlichkeit von 95% zustande käme. Ich glaube also nicht dass deine Aussage stimmt, oder ich verstehe nicht warum sie stimmen sollte.
@sebi:
Ich glaube, wir verstehen den Satz tatsächlich verschieden?
Ich habe bei der Fragestellung an jemand gedacht, der einen Test entwirft und im Voraus eine Schwelle für die Auswertung festlegen will. Dabei will er sicherstellen, dass der Test nur wenige, falsch positive Ergebnisse liefert. Also möchte er sicherstellen, dass – wenn die Nullhypothese zutrifft – nur in wenigen (5%) der Fälle der Test dennoch positiv ausfällt.
Mathematisch formuliert läuft es auf eine bedingte Wahrscheinlichkeit raus. Unter der Bedingung, dass die Nullhypothese zutrifft, soll mit einer Sicherheit von 95% der Test kein positives Ergebnis liefern.
Was man mit den Angaben in der Aufgabe nicht beantworten kann, ist die Frage „Wenn der Test ein positives Ergebnis liefert, wie hoch ist die Wahrscheinlichkeit, dass die Nullhypothese nicht zutrifft, also wirklich ein Effekt vorliegt?“
Dazu müsste man wissen,
– wie hoch die Wahrscheinlichkeit ist, dass der Test einen Effekt korrekt erkennt (wenn man den Effekt nicht kennt und nicht weiß, wie groß der Effekt ist, dann kann man diese Wahrscheinlichkeit nur abschätzen) und
– wie hoch die Grundwahrscheinlichkeit ist, dass überhaupt ein Effekt auftritt.
Die Rechnung dazu kann man im Link zur Bayesformel finden.
Die Rechnung zeigt dann auch, dass, wenn man unwahrscheinliche Effekte sucht, dann die meisten positiven Testergebnisse falsche Positive sind.
Insgesamt denke ich haben wir das gleiche Verständnis, mir gehts nur um die Formulierung die meiner Meinung nach irreführend ist.
Ich zitiere dich noch einmal, du schreibst: „dass ein positives Behandlungsergebnis mit einer Sicherheit von mindestens 95% nicht durch Zufall entstanden ist, also signifikant ist”.
Du meinst aber „dass ein nicht positives Behandlungsergebnis mit einer Sicherheit von mindestens 95% durch Zufall entstehen würde, also signifikant ist”.
Der Satz schaut jetzt umständlich aus, aber ich wollte damit klar machen, wo meiner Meinung nach der Fehler liegt: das „nicht“ ist an der falschen Stelle, und das macht einen Unterschied. Zusätzlich habe ich noch den Konjunktiv eingefügt, da ja generell unklar ist, ob Zufall regiert (also die Nullhypothese) oder nicht.
Schaut jetzt zwar wie Korinthenkackerei meinerseits aus, aber ich finde das enorm wichtig. Denn der Fehler, der dir hier nur in der Formulierung unterläuft, ist der Kardinalfehler den die meisten statistisch unbedarften Menschen beim p-Wert machen. Daher sollte man hier sehr aufpassen, dass sich das nicht noch weiter verbreitet.
@sebi:
Ich habe das Gefühl, wir sind noch nicht ganz beieinander.
Und ich vermute, es liegt weniger am Satz als an den impliziten Annahmen.
Was weder in Deiner noch in meiner Formulierung explizit gesagt wird, ist, welchen der beiden folgenden Fälle man betrachten will:
– Man geht davon aus, dass die Nullhypothese zutrifft. Dann kann man sich fragen, wie oft durch Zufall ein bestimmtes Ergebnis zustande kommt. Das kann man dann auch ohne Weiteres ausrechnen, denn die Nullhypothese kennt man.
So was wie eine Überlegung im Voraus.
oder
– Man stellt sich vor, man hat das Experiment gemacht und ein bestimmtes Ergebnis erhalten. Dann kann man sich fragen, wie sicher man von dem Ergebnis darauf schließen kann, ob die Nullhypothese zutrifft oder nicht. Dazu muss man aber eine Alternative zur Nullhypothese annehmen und diese beschreiben (wie wahrscheinlich war die Alternative vor dem Test und wie groß ist der Effekt (Wahrscheinlichkeit für Behandlungserfolg) bei zutreffender Alternative.
Eher eine Analyse im Nachhinein.
Bei meiner Rechnung bin ich vom ersten Fall ausgegangen.
Ich bin mir nicht sicher, aber Dein Konjunktiv hört sich für mich so an, sla ob Du den zweiten Fall annimmst? (Im ersten Fall ist es ja die Voraussetzung, dass ich von der Nullhypothese ausgehe.)
@sebi:
Das ist doch die Frage, ob die eine Aussage die doppelte Verneinung der anderen Aussage ist.
Ein Ergebnis ist entweder zufällig entstanden oder nicht – tertium non datur. Und Ergebnisse hat man auch nur positive oder negative. Wieso soll das hier unzulässig sein?
@Sebi @Peter
Ich denke, beide Formulierungen sind nicht ganz korrekt (und die zweite macht es mit der doppelten Verneinung eher noch schlimmer).
Diese Formulierung von @Peter trifft es ziemlich gut:
Mit konkreten Wahrscheinlichkeitswerten ausgedrückt bedeutet das: Die Wahrscheinlichkeit, dass die Nulhypothese zutriffe (also dass unserere Daten durch Zufall entstanden sind obwohl kein Effekt vorliegt) kleiner als 5% ist. Das und nichts anderes kann man aussagen wenn die statistische Analyse einen p-Wert kleiner 0.05 ergibt.
Das lässt aber nur den Umkehrschluss zu, dass mit 95% Wahrscheinlichkeit irgendein Effekt vorliegt (das könnte aber auch das Wetter gewesen sein).
Der Umkehrschluss, dass mit 95% ein Behandlungserfolg vorliegt ist nicht korrekt. Das ist genau der Grund, warum ein gutes Studiendesign und viele zusätzliche Kontrollen so wichtig sind. Nur indem wir so viele andere Ursachen wie möglich ausschliessen, können wir einigermassen sicher sein, dass der beobachtete Effekt auf unserer Behandlung beruht und nicht auf irgendeinem anderen Faktor. Es kommt aber eben immer wieder vor, dass doch irgendein Faktor vorlag, den man beim Design des Experimentes/der Studie übersehen hat. Das ist der Hauptgrund für „falsche“ Ergebnisse. Es sind (von Aufzeichnungsfehlern oder absichtlichen Fälschungen mal abgesehen) eigentlich nie die Daten die falsch sind sondern fast immer die Interpretation der Daten.
Das ist auch der Grund, warum Studien mit menschlichen Teilnehmern so schwierig sind. Oft sind nämlich die besten Kontrollen unethisch und damit nicht durchführbar. Damit will ich nicht sagen, dass wir die Ethik über Bord werfen sollen, ich will nur betonen, warum es in der Psychologie und bei klinischen Studien häufiger vorkommt das Ergebnisse falsch interpretiert werden als in anderen wissenschaftlichen Disziplinen.
Lol jetzt ist die Verwirrung komplett.
@Peter: ich bin in meinen „korrigierten“ Zitaten immer von Fall 1 ausgegangen, und habe gerade deinen Fehler darin gesehen, dass du Fall 2 angenommen hast (nur in der Formulierung, ich weiß dass du es nicht so gemeint hast).
@userunknown: Die Aussagen sind eben nicht äquivalent, daher ist natürlich auch nicht eine die doppelte Verneinung der anderen.
@Till: ich denke, mein zweites Zitat ist weitgehend korrekt. Der Rest ist mir klar.
@sebi
Sorry, aber der Satz ist schlicht falsch. Dass er so kompliziert formuliert ist, macht es auch nicht besser. Ein „nicht positives Behandlungsergebnis“ kann nicht signifikant sein, da es der Nullhypothese entspricht.
Sry, da hast du schon recht, der Nebensatz muss natürlich noch weg. Den hab ich nur dringelassen, um das ursprüngliche Zitat möglichst wenig zu verfälschen. Dann passts aber.
@sebi
wenn ich Dich richtig verstehe meinst Du folgendes: „dass ein nicht positives Behandlungsergebnis mit einer Sicherheit von mindestens 95% durch Zufall entstehen würde“
Aber auch das ist leider kein gültiger Umkehrschluss der Nullhypothese.
Statistik hat nichts mit hypothetischen „nicht positiven Behandlungsergebnissen“ (sprich nicht positiven Datensätyen) zu tun. Es geht um zwei ganz konkrete Datensätze und eine Nullhypothese:
Ich versuche das nochmal aufzudröseln:
Die Nullhypothese besagt: Unsere Gruppe, die mit dem Wirkstoff behandelt wurde (Datensatz 1) liefert die gleichen Ergebnisse wie die Kontrollgruppe (Datenstz 2). Statistisch Ausgedrückt bedeutet das: Die Nullhypothese geht davon aus, dass die Ergebnisse der behandelten Gruppe aus der gleichen statistischen Verteilung stammen wie die Ergebnisse der Kontrollgruppe. Der p-Wert der statistischen Analyse gibt nun an, wie hoch die Wahrscheinlichkeit dafür ist, dass die Nullhypothese zutrifft. Statistik beschäftigt sich immer mit konkreten Datensätzen und macht keine aussagen über die Wahrscheinlichkeit mit der irgendwelche anderen Datensätze auftreten.
Der einzige gültige Umkehrschluss ist also, dass die Behandelte und die Kontrollgruppe nicht aus der gleichen Verteilung stammen. Das Bedeutet, es gibt irgendeinen unbekannten Unterschied zwischen den Gruppen. Sobald wir daraus Rückschlüsse ziehen, mit welcher Wahrscheinlichkeit ein Behandlungserfolg eintritt (oder auch nicht) machen wir einen Denkfehler.
Es wäre ja schön gewesen den Fehler durch ein einfaches Verschieben eines „nicht“ zu korrigieren, aber ich fürchte, Du musst Dich von diesem Gedanken verabschieden.
Wenn die Nullhypothese zutrifft, liegt die Wahrscheinlichkeit, bei einer Studie mit einem p-Wert von 0.05 ein positives Studienergebnis zu erziehlen, bei 0.05. Somit liegt bei einer solchen Studie die Wahrscheinlichkeit, ein negatives (a.k.a. nicht positives) Ergebnis zu erziehlen, bei 0.95.
Stimmen wir soweit überein?
@sebi
Nein stimmen wir nicht. Es geht bei Statistik nicht darum, zukünftige Ergebnisse vorherzusagen. Es geht darum bei bestehenden Ergebnissen zu berechnen mit welcher Wahrscheinlichkeit die Nullhypothese zutrifft. Diese Wahrscheinlich hängt immer von den konkreten Zahlenwerten der Kontrollgruppe und der Behandelten Gruppe ab. Es also keine „Studie mit einem p-Wert von 0.05“. Es gibt nur Ergebnisse bei denen der p-Wert 0.05 beträgt (was bedeutet, dass mit 5% Wahrscheinlichkeit der beobachtete Unterschied zwischen Kontrolle und behandelter Gruppe reiner Zufall ist).
Ich hab mich wohl zu unpräzise ausgedrückt. Mit „einer Studie mit einem p-Wert von 0.05“ meinte ich eine Studie, deren Ergebnis dann als positiv definiert wird, wenn die erzielten Daten einen p-Wert von 0.05 oder weniger aufweisen.
Im Lichte dieser Definition, würdest du mir nun zustimmen?
@sebi
Ich versuche mal Deine beiden letzten Aussagen zusammenzufassen:
Dieser Aussage kann ich leider immer noch nicht zustimmen, denn die Wahrscheinlichkeit mit der ein signifikantes (Du nennst das „positiv“) Ergebnis erzielt wird hängt selbst wenn die Nullhypothese stimmt (d.h. beide Datensätze aus der gleichen Verteilung stammen) noch von der Streuung der Daten und der Anzahl der Datenpunkte ab.
Noch einmal: Statistik macht keine Vorhersagen, sie analysiert vorhandene Daten.
@Sebi Damit kann ich leben. Nichts für ungut.
@Peter H Mir ist gerade aufgefallen, dass im Text ja noch viel mehr Information gegeben ist. In dem Fall (Erwartungswert genau bekannt, Gruppengröße bekannt) und unter den Annahme, dass die Studie auch ansonsten vernünftig durchgeführt wird, dann ist Dein Satz so wie er im Text steht meines Erachtens völlig richtig.
@sebi:
Die Formulierung in Beitrag #37 stimme ich so zu – und dort ist ausdrücklich formuliert, dass man von der Nullhypothese ausgeht (Fall 1).
War das der wesentliche Punkt aus Deinem Einwand oder übersehe ich noch etwas anderes?
@Till: lassen wirs gut sein. Nur fürs Protokoll, ich stimme den meisten deiner Aussagen auch nicht zu, aber das ist mir jetzt zu mühselig.
@Peter H.: Mein Kernproblem bleibt immer noch das ursprüngliche mit deiner Formulierung. Wenn du mit “dass ein positives Behandlungsergebnis mit einer Sicherheit von mindestens 95% nicht durch Zufall entstanden ist, also signifikant ist” tatsächlich das ausdrücken wolltest, was ich in #37 formuliert habe, dann ist das meiner Meinung nach nicht gelungen.
Dein Satz scheint mir eigentlich nur so sinnvoll interpretiert werden zu können, wie ich es oben schon getan habe. Und zwar so, dass die Nullhypothese mit einer Wahrscheinlichkeit von 0.05 korrekt ist. Und das ist natürlich falsch, wie du ja selbst weißt und in deinem Text erklärt hast.
@sebi:
Was stört Dich an der Interpretation, dass es um eine Analyse im Voraus geht bzw. wie würdest Du den Fall 1 formulieren, ohne zu viel von der Lösung vorzugeben?
Naja, was mich stört ist, dass diese Interpretation schlicht falsch ist. Die Wahrscheinlichkeit, dass die Nullhyphothese zutrifft, ist nicht 0.05 sondern gänzlich unbekannt. Formulieren würde ich es wie in #37 geschehen.
Ich habe allerdings das Gefühl, dass wir mittlerweile komplett aneinander vorbeireden. Bist du nicht der Meinung, dass die Interpretation falsch ist?
@sebi:
Ich denke auch, wir reden aneinander vorbei.
Meiner Meinung nach wird weder im Fall 1 noch im Fall 2 jemals angenommen, dass die Wahrscheinlichkeit, dass die Nullhypothese zutrifft 95% ist, und ich weiß auch nicht, woraus Du das abliest?
Im Fall 1 wird angenommen, dass die Nullhypothese zutrifft und genau dann stimmt auch die nachfolgende Rechnung und im Fall 2 muss man für die Analyse – wie beschrieben – die Wahrscheinlichkeit der Nullhypothese voraussetzen.
Ok, somit sind wir wieder zurück auf Anfang. Ich zitiere mich selbst:
[Du schreibst “dass ein positives Behandlungsergebnis mit einer Sicherheit von mindestens 95% nicht durch Zufall entstanden ist, also signifikant ist”, was denke ich nicht korrekt ist.
Ich zumindest interpretiere das folgendermaßen: “Die Wahrscheinlichkeit, dass die Nullhypothese nicht zutrifft, ist 95 %”.]
Exakt diese Interpretation ist und war immer das einzige Problem, das ich ansprechen wollte. Und ich sehe nicht wie man das anders interpretieren soll.
@sebi:
Ich denke auch, wir drehen uns im Kreis.
[…] Linien überlagert mit der Verteilung des leuchtenden Gases. Man sieht deutlich (die gemessene Signifikanz ist 8σ!), dass das abgebremste Gas mehr in der Mitte der beiden Galaxienhaufen konzentriert ist, […]